2024. 2. 20. 17:18ㆍML
K-Nearest Neighbors (KNN)
최근접이웃 알고리즘
현재 데이터와 가장 가까운 k개의 데이터를 찾아서 가장 많은 분류값으로 분류하는 알고리즘
k개의 가장 가까운 이웃 데이터에 의해 예측된다는 의미
instance-based learning으로 내부 모델을 구성하지 않고 단순히 훈련데이터의 인스턴스를 저장
분류는 각 포인트의 가장 가까운 이웃의 단순 과반수 투표로 계산됨
k 값에 따라 분류가 달라질 수 있다는 점이 특징

위 그림의 경우 가장 가까운 3개의 기존 데이터의 분류를 살펴본 결과,
B분류가 2개, A분류가 1개이므로 새로운 데이터는 B분류로 할당
동작원리
전처리
원핫인코딩
거리기반 계산을 활용한 알고리즘이기에 명목형 변수를 수치형 변수로 변형해줘야함
선형회귀나 로지스틱 회귀에선 다중공선성문제를 일으키지만 KNN에선 문제 되지않음
데이터 표준화
레코드 간의 유사성 측정은 두 벡터사이의 거리 계산을 통해 측정
상대적으로 큰 스케일에서 특정된 변수들이 측정치에 미치는 영향이 클 수 있음을 의미
-> 데이터 표준화 (스케일 조정)을 통해 해결
표준화 과정 적용시 각 변수가 예측력 측면에서 갖는 중요성이 모두 같다는 의미를 가짐
표준화 방법은 다양함 (ex. StandardScaler())
* 정규화(표준화)과정은 기존 데이터 분포에 영향을 미치지 않음
k 선택하기
성능을 결정하는 중요한 요소
너무 작으면 노이즈 성분까지 고려하는 오버피팅,
너무 크면 과하게 평탄화되어 데이터의 지역정보를 예측하는 knn의 기능을 잃어버림
오버피팅과 오버스무딩 사이의 최적의 k값을 찾기 위해 정확도 지표를 사용
홀드 아웃 데이터에서 정확도를 측정해 k값 결정하는데 사용
데이터에 노이즈가 없고 잘 구조화된 데이터의 경우 k값이 작을수록 잘 동작,
노이즈가 많은 겅우 k값이 클수록 좋음
-> k값 결정하기 전에 데이터 전처리로 노이즈 줄이는 것이 중요
보통 동률이 나오는 것을 방지하기위해 k값을 홀수나 데이터 수의 제곱근만큼 설정하기도 함
데이터의 위치 즉 벡터 공간에서 두 벡터의 거리를 기반으로 가깝고 멀다는 것을 구분하면 된다
-> 거리 측정할 때 유클리드 거리를 많이 사용
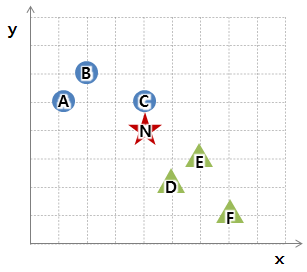
k = 1일 경우, 가장 가까운 C만 고려 -> 동그라미로 분류

k = 2일 경우, C,D,E고려 -> 다수결로 세모로 분류

k = 5인 경우, C,D,E,B,A까지 고려 -> 다수결로 동그라미로 분

거리측정법
관측 데이터 간 유사성이나 근접성을 측정하기 위한 데이터간의 거리 측정법

유클리드 거리
L2 distance
두 점 사이의 거리를 계산할 때 흔하게 쓰이는 방법
최단거리를 구하는 방법
맨하튼 거리
L1 distance, 택시 거리 또는 시가지 거리로 불림
유클리드 거리와 달리 차원의 차를 제곱하지 않고 절댓값의 합으로 나타낸다
맨하튼이란 이름 유래처럼 몇블록 이동했는지를 계산하는 metric
유클리드 거리보다 현실적인 거리
표준화 거리

각 변수를 해당 변수의 표준편차로 척도 변환한 후에 유클리드 거리를 계산한 거리
표준화를 하게 되면 척도 (scale)의 차이, 분산의 차이로 인한 왜곡을 피할 수 있음
민코우스스키 거리
유클리드 거리, 맨하튼 거리를 일반화한 거리
m제곱한 후 m제곱근을 씌워주는 거리
두 성분 중 더 크게 떨어진 성분으로 수렴하게 된다
많이 떨어진 특성을 부각시킬때 사
마할라노비스 거리


각 변수의 분산과 공분산(상관성)구조를 함께 고려한 통계적 거리
유클리드 거리의 경우 중심~ 점1의 거리가 중심~점2의 거리보다 가까움
마할라노비스 거리는 변수들의 상관관계가 거리에 영향을 미쳐
확률등고선을 보면 중심에서부터 관측될 가능성이 더 높은 점2와의 거리가 더 가깝다고 생각함
-> 두 변수간 높은 상관관계가 있다면 유용하나 복잡성이 증가
고려해야 할 점
- 적절한 k값
작은 k값은 노이즈에 민감하게 반응할 수 있고, 큰 k값은 결정경계를 부드럽게 만들 수 있으나
클래스 사이의 경계를 흐리게 할 수 있음 - 적절한 거리 측정 방법을 선택
데이터 셋의 특성에 따라 다른 거리 측정방법을 선택 -> 성능에 영향 - 데이터 정규화
데이터 분포에 민감한 모델
데이터가 고차원이거나 특성 간 상관관계가 있는 경우 정규화하는 것이 중요
-> 상대적으로 큰 스케일에서 측정된 변수들이 측정치에 미치는 영향이 커서 정규화 필
스케일링 작업을 수행하거나 주성분 분석같은 차원 축소 기법을 적용해 전처리해줌 - 데이터 셋의 크기에 따라 모델을 조정해야함
데이터 셋 크기가 커지면 계산 비용이 증가
KNN 장점
- 간단하다 (수식이 간단하고 이해하기 쉽다)
- 숫자로 구분된 속성에 우수한 성능을 보인다
거리, 횟수같은 수치형 레이블에 대해 높은 정확도를 기대할 수 있음 - Lazy learning의 특성이 있음
실제 예측 시점에서 계산을 진행하기 때문에 별도의 모델이 사전 학습을 할 필요 없음 - 다중 분류에도 적용가능
KNN 단점
- Lazy learning의 trade-off로 연산속도가 다른 알고리즘에 비해 아주 느리다
- 하나의 분류를 진행할때마다 전체 데이터와 비교해야하기 때문에 데이터 차원에 따라 연산속도가 크게 늘어남
- 다른 알고리즘에 비해 데이터의 편향성, 이상치에 민감
- 적절한 K값 찾아내는 것이 중요
차원의 저주
차원이 증가할수록 학습 데이터의 수가 차원의 수보다 적어져 알고리즘의 성능이 저하되는 것을 의미
차원이 증가하면 공간의 부피가 너무 빨리 증가하여 사용가능한 데이터가 희소해진다는 것
차원이 증가할수록 변수가 증가하고 개별 차원 내에서 학습할 데이터 수가 적어진다
-> 변수가 증가한다고 반드시 발생하는 것은 아님
관측치보다 변수 수가 많아지는 경우에 차원의 저주가 발생

1차원에서 데이터 밀도가 촘촘했던 것이 차원이 증가하면서 데이터 간 거리가 멀어진다
이렇게 차원이 증가하면 빈 공간이 생김
빈공간은 0으로 채워진 공간으로 정보가 없는 공간
빈공간이 많을수록 학습시켰을 때 모델 성능이 저하됨
고차원 공간은 공간이 많아 훈련데이터가 서로 멀리 떨어져 있고
새로운 샘플도 훈련 샘플과 멀리 떨어져 있을 가능성이 높다
-> 예측을 위해 보외법을 사용, 그러나 오버피팅 가능성이 높음

보외법 : 이용가능한 자료의 범위가 한정되어 있어 그 범위 이상의 값을 구할 수 없을때
관측된 값을 이용해 한계점 이상의 값을 추정하는 것을 의미
그림의 경우 A~B까지의 범위만 주어져 있을 때 P값을 이용해 Q값을 예측하는 것
-> 예측 정확도가 떨어짐
KNN은 차원의 저주문제에 치명적이다
차원이 커질수록 주변 이웃들이 멀어지니 예측에 사용할 포인트 값이 한참 떨어져 있어
모델 성능도 나빠지고 설명력도 좋지 않게됨
해결방안
- 더 많은 데이터를 모아 훈련 세트의 크기를 키우는 것 (사실상 불가능)
차원이 크더라도 엄청난 양의 데이터를 모을 수 있다면 데이터의 밀도가 높아짐
- 일정 밀도에 도달하기 위해 필요한 훈련 샘플 수는 차원의 수가 커짐에 따라 기하 급수적으로 늘어남 - 차원 축소 방법을 사용 - PCA같은 방법을 사용해 특징 수를 줄일 수 있음 (현실적인 해결방안)
-그러나 일부 정보가 유실되기에 성능이 조금 나빠질 수 있음

parameter
- n_neighbors : Number of neighbors to use, default = 5
- weights : Weight function used in prediction, default = 'uniform', ‘{uniform’, ‘distance’}
- algorithm : Algorithm used to compute the nearest neighbors, default = 'auto', {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}
- p : Power parameter for the Minkowski metric, default = 2
p =1->manhattan_distance (l1), p = 2-> euclidean_distance (l2) - metric : Metric to use for distance computation, default = 'minkowski'
참고 및 출처 : https://sirzzang.github.io/ai/AI-KNN/ , https://syj9700.tistory.com/8 , https://ineed-coffee.github.io/posts/KNN/ , https://for-my-wealthy-life.tistory.com/40 , https://mozenworld.tistory.com/entry/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-%EB%AA%A8%EB%8D%B8-%EC%86%8C%EA%B0%9C-3-KNN-K-Nearest-Neighbor , https://rfriend.tistory.com/199 , https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
'ML' 카테고리의 다른 글
| XGBoost (0) | 2024.02.18 |
|---|---|
| ExtraTrees (0) | 2024.02.18 |
| RandomForest (0) | 2024.02.17 |
| Decision Tree (0) | 2024.02.17 |
| LightGBM (0) | 2024.02.12 |