2024. 2. 18. 17:22ㆍML
Extratrees
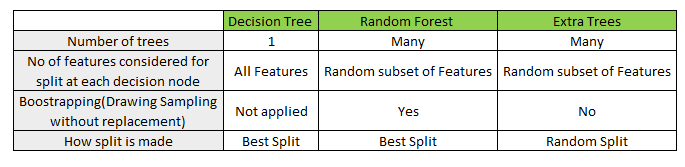
Decision Tree를 기반으로 한 앙상블 학습방법
극도로 무작위화된 기계학습방법
Bootstrap을 사용하지않음
즉, 각 결정트리를 만들어낼 때 전체 훈련세트를 사용하는 것으로
분할할 때 가장 좋은 분할을 찾는 것이 아닌 무작위로 분할한다는 것
데이터 샘플 수와 특성 설정까지 랜덤
결정트리에서 특성을 무작위로 분할하게 되면 성능은 낮아진다는 단점있으나
많은 트리를 앙상블하기때문에 오버피팅을 막고 검증세트의 점수를 높이는 효과가 있다
랜덤포레스트와 차이
bootstrap을 사용하지 않음 - 전체 특성 중 일부를 랜덤하게 선택해 노드분할
결정트리를 만들어 낼 때 훈련세트 전체를 사용하기 때문에 baggin이라 할 수 없음
랜덤포레스트는 주어진 모든 특성에 대한 정보이득을 계산하고 가장 높은 정보 이득을 가지는
특성을 분할노드로 선택하고 전부 비교해 가장 최선의 특성을 선택
- 성능이 좋은 트리를 만들 수 있지만 연산량이 많이 든다는 단점
엑스트라 트리는 분할 시 무작위로 특성을 선정
특성 중 아무거나 고른 다음 그 특성에 대해 최적의 노드로 분할
- 성능이 낮아지나 생각보다 준수한 성능을 보이고 오버피팅을 막고 검증 세트의 점수를 높히는 효과있음
무작위성이 좀 더 커 더 많은 결정트리를 훈련해야함 -> 그러나 속도가 빠름
랜덤포레스트보다 미세하게 성능이 좋음
Extra trees - 임의분할, Randon Forest - 최적분할
즉, 랜덤포레스트는 특성선택 시 개별 모델에 대한 차원을 줄임
반면에 엑스트라 트리는 각 노드에서 랜덤하게 독립변수를 선택
sklearn에서 사용

parameters
- n_estimators : the number of trees in the forest
- criterion : to measure the quality of a split, {“gini”, “entropy”, “log_loss”}, default=”gini”
- max_depth : The maximum depth of the tree
- min_samples_split : The minimum number of samples required to split an internal node
- oob_score : to use out-of-bag samples to estimate the generalization score, default=False
- n_jobs : The number of jobs to run in parallel, -1 means using all processors
참고 및 출처 : https://yumdata.tistory.com/377 , https://erdnussretono.tistory.com/49 , https://statinknu.tistory.com/29 ,
'ML' 카테고리의 다른 글
| K-Nearest Neighbors (0) | 2024.02.20 |
|---|---|
| XGBoost (0) | 2024.02.18 |
| RandomForest (0) | 2024.02.17 |
| Decision Tree (0) | 2024.02.17 |
| LightGBM (0) | 2024.02.12 |