2024. 2. 2. 17:51ㆍML
Cross Validation (교차검증)
주어진 데이터셋에 학습된 알고리즘이 얼마나 잘 일반화되어있는지 평가하기 위한 방법
일반적으로 train / test set으로 나눠 모델을 검증 (Holdout method)
-> 고정된 test set을 통해 모델의 성능을 검증하고 수정하는 과정을 반복하면 결국 test set에만 잘 동작하는 모델이 됨
즉, test set에 과적합하게 되므로 다른 데이터를 가져와 수행하면 결과가 나쁠 수 있음
>> 해결책 : Cross Validation = train set을 train set + validation set으로 분리한 후 validation set을 사용해 검증하는 방법
▶ Validation set은 학습에 영향을 미치는가?
학습 모델은 가중치를 업데이트 하면서 학습한다.
validation set 은 한 epoch을 돈 뒤 학습이 잘 되었는지 확인하는 역할로, 가중치 업데이트에는 영향을 미치지 않음
| train set | validation set | test set | |
| 학습 과정에 참조할 수 있는가 | O | O | X |
| 모델의 가중치 설정에 이용되는가 | O | X | X |
| 모델의 성능 평가에 이용되는가 | X | O | O |
cross validation를 하는 이유 (필요성)
과적합을 피하서 파라미터를 튜닝하고 일반적인 모델을 만들고 더 신뢰성있는 모델 평가를 진행하기 위함
장점
모든 데이터셋을 훈련에 사용할 수 있음
- 정확도를 향상시킬 수 있음
- 데이터 부족으로 인한 과적합을 방지할 수 있음
모든 데이터셋을 평가에 활용할 수 있음
- 평가에 사용되는 데이터 편중을 막을 수 있음
- 평가 결과에 따라 좀 더 일반화된 모델을 만들 수 있음
단점
literation 횟수가 많아 모델 훈련/ 평가 시간이 오래 걸림
cross_val_score()
Cross Validation을 사용하는 가장 간단한 방법

parameter
- estimator : 모델을 나타내는 객체, classifier 종류면 내부적으로 stratified k fold로 진행됨
- X : 특징을 나타내는 데이터셋
- y : 레이블을 나타내는 데이터셋
- scoring : 예측 성능 평가 지표 ,
- cv : fold의 수 결정, 교차 검증 폴드
K - Flod Cross Validation

가장 일반적으로 사용되는 교차검증 방법
보통 회귀모델에 사용되며 데이터가 독립적이고 동일한 분포를 가진 경우 사용
1. 전체 데이터셋을 train set과 test set으로 나눈다.
2. train set을 train set + validation set으로 사용하기 위해 K개의 폴드로 나눈다.
3. 첫번째 폴드를 validatio set으로 사용하고 나머지를 train set으로 사용한다.
4. 모델을 학습한 뒤 첫번째 폴드인 validation set으로 평가한다.
5. 차례대로 다음 폴드를 validation set으로 사용해 반복한다.
6. 총 K개의 성능 결과가 나오며, K개의 평균을 학습 모델의 성능이라 한다.
문제점 : 데이터 편향이 존재하는 경우 제대로된 학습,검증이 이뤄지지 않음
-> shuffle = True로 설정해 데이터셋을 섞어줌 or Stratified K - Fold Cross Validation 사용

parameter
- n_splits : number of folds
- shuffle : shuffle the data, default = False
- random_state : when shffle is True, affects the ording of the indices
Repeated K - Fold

K -Fold를 n회 반복
Leave One Out (LOO)


validation set을 한개로 하고 나머지를 train set으로 해서 하나씩 모두 검증하는 방법
n개의 데이터에서 1개를 test set으로 정하고 나머지 n-1개의 데이터로 모델링
-> 데이터 수 n이 크다면 n번의 모델링을 진행해 시간이 오래 걸림
Leave P Out (LPO)


Leave One Out과 비슷, p를 parameter로 넣어줘야
p개의 데이터를 선택해 모델 검증에 사용
nCp : test set을 구성할 수 있는 경우의 수
데이터가 많을수록 오래 걸림
Random permutations cross validation ( Shffle & Split)

데이터셋 인덱스를 무작위로 사전에 설정한 비율로 분할

parameter
- n_splits : number of folds
- test _size : 0.0 ~ 1.0 사이 값, test set 비율
- train_size : 0.0 ~ 1.0 사이 값, train set 비율
- random_state : affects the ording of the indices
반복횟수와 각 샘플비율을 세밀하게 제어할 수 있어 k-fold cross validation의 좋은 대안
Stratified Sampling (계층적 샘플링)
모집단의 데이터 분포 비율을 유지하면서 데이터를 샘플링하는 것
모집단을 여러개의 층으로 구분하여 각 층에서 n개씩 랜덤하게 추출하는 방법
-> 단순한 무작위 샘플링 방식은 편향 발생 가능성 있음
train / test / validation data를 일정한 비율로 나눠 구분할 때 적용
필요한 이유 : 데이터가 편향되어 있을 경우 학습의 일반화가 제대로 진행되지않기 때문

parameter
- n_splits : number of folds
- test _size : 0.0 ~ 1.0 사이 값, test set 비율
- train_size : 0.0 ~ 1.0 사이 값, train set 비율
- random_state : affects the ording of the indices
Stratified K - Fold Cross Validation (계층별 K겹 교차검증)
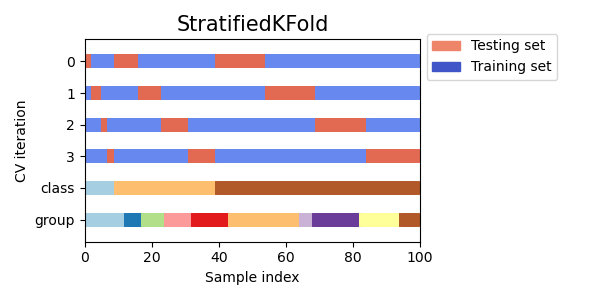
원본 데이터의 전체 레이블 분포를 학습 및 검증 데이터셋에 반영해줌 - 레이블 분포도가 유사하도록 validation set을 추출
데이터가 편향되어있을 경우 사용
-> 특정 레이블값이 특이하게 많거나 적어서 값의 분포가 한쪽으로 치우치는

parameter
- n_splits : number of folds
- shuffle : shuffle the data, default = False
- random_state : when shffle is True, affects the ording of the indices
참고 및 출처 : https://kyhh1229.tistory.com/entry/%EA%B5%90%EC%B0%A8%EA%B2%80%EC%A6%9D-crossvalscore , https://blog.naver.com/PostView.nhn?blogId=winddori2002&logNo=221850530979 , https://scikit-learn.org/stable/modules/cross_validation.html , https://wooono.tistory.com/105 , https://huidea.tistory.com/30 ,
'ML' 카테고리의 다른 글
| Bagging (0) | 2024.02.10 |
|---|---|
| Voting (0) | 2024.02.10 |
| Hyper Parameter (0) | 2024.01.28 |
| Tuning The Hyper Parameter - RandomizedSearchCV (0) | 2024.01.28 |
| Tuning The Hyper Parameter - GridSearchCV (0) | 2024.01.28 |