2023. 10. 3. 18:20ㆍDL/DL_Algorithm
목차
Optimization
어떤 objective function(대상이 되는 함수)의 함숫값을 최적화(최대/최소화)시키는
parameter조합을 찾는 문제
최대화 : 소요시간,비용인 경우 / 최소화 : 성능,이윤인 경우
Output이 목표로 하는 타겟값과 가까워지도록 loss function을 설정하고 error가 줄어드는 방향으로 학습시키기위해
1) 각 weight와 gradient값을 계산 2) 앞의 값들을 이용해 weight를 다시 설정
1),2)를 반복하며 최적의 weight값을 갖는 모델을 찾아내는 과정
Optimizer
Loss의 최솟값을 찾아가는 알고리즘
- 학습속도를 빠르고 안정적이게 하는 것이 목표
Optimizer 종류
1. Gradient Descent (경사하강법)

가장 기본적이고 많이 사용되는 알고리즘
함수(J)의 최솟값을 찾는 최적화 기법
최소 loss func값 찾기위해 gradient를 따라 내려가면서 기울기 반대방향으로 일정크기만큼
이동하는 것을 반복하며 weight를 업데이트해 최솟값을 찾는 방법
→ 함수가 한번에 얼마나 줄어들게 하는지 결정하는 parameter(learning rate)를 정해야함
너무 작으면 최적화가 오래 걸리고 너무 크면 최솟값을 지나쳐버림
학습률(learning late): 경사 하강법에서 중요한 파라미터로 스텝의 크기를 나타낸다. 학습률이 너무 작으면 알고리즘이 수렴하기 위해 반복을 많이 진행해야 하므로 시간이 오래 걸리고, 학습률이 너무 크면 골짜기를 가로질러 반대편으로 건너뛰게 되어 이전보다 더 큰값으로 발산하게 만들 수 있다.
단점
- 모든 자료의 기울기를 다 검토하기에 dataset이 클수록 계산량이 너무 커짐
- 전체에서 최소가 되는 부분인 Global Minimum을 찾는 것이 묙표이나,
Local Minimum을 찾았을 때 업데이트과정이 끝남
2. Newton Method
방정식 f(x) = 0의 해를 근사적으로 찾을 때 유용하게 사용되는 방법
뉴턴법(Newton's method)/뉴턴-랩슨법(Newton-Raphson method)은
현재 x값에서 접선을 그리고 접선이 x축과 만나는 지점으로 x를 이동시켜 가면서 점진적으로 해를 찾는 방법이다.

그러나 실제 DNN 학습에는 많이 쓰이지 않는다.
-> Δ𝑥𝑛𝑡=−𝐻𝑥−1∇𝑓𝑥=−𝑓′(𝑥)/𝑓′′(𝑥)
gradient 뿐만 아니라 Hessian도 미리 알아함
Optimizer의 난제
1. Local Minimum/ Maximum

Optimizer의 목표는 Global Minimum을 찾는것이나,
loss func의 수많은 Local Minimum 중 Global minimum에 해당하지않는 Local Minimum을 찾는 것
→ 경사를 따라 하강하다 Local Minimum을 Global minimum으로 판단
2.Oscillation
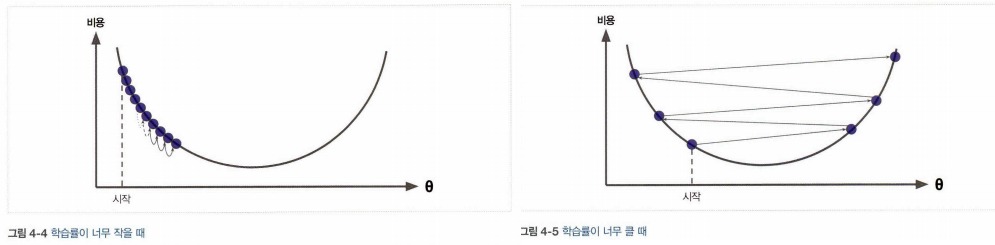
Learning Rate(=LR)이 낮으면 천천히 수행되나 LR이 높으면 빠르게 가는 대신 최솟값 근처에서 왔다갔다 할 수 있다
왔다갔다하면서 시간낭비하는 현상 -> Osillation
>> 해결방안 : 뉴턴방법, SGD
3. Saddle Point

다변수 실함수의 변역에서 어느 방향으로 보면 극대값이지만 다른 방향에서 보면 극소값이 되는 점
양방향 기울기가 모두 0인데도 불구하고 최대/최소가 되지않는 경우
-> 최댓값인지 최솟값인지 구분못하고 학습을 종료하는 경우 발생
4.Cilff

큰 weight들이 반복해서 곱해지는 깊은 비션형 신경망(RNN계열)은 목적함수공간에
급한 비선형구간이 존재하는 경우가 있다.
절벽에 가까워지면 GD갱신단계에서 parameter가 급격히 변해 gradient가 갑자기 커지므로 이때까지의
최적화 결과가 무의미해지는 문제 발생
>> 해결방안 : gradient clipping 등 weight normalization을 통해 해결
5. Long - Term Dependency
가중치를 매 layer마다 반복하는 RNN계열의 경우 sequence data의 길이가 길어질수록
과거의 중요한 정보에 대한 학습이 어려워지는 문제가 생김
>>해결방안 : 1. SGD로 대체, 2. LSTM,GRU같은 RNN모델 고안
6. Plateau

GD를 타고 Global minimum을 향해 나아가는데 평지(Plateau)가 생겨 통통 튀다가 더이상 loss가 업데이트되지 않는 현상
Local Minimum에 비해 발생확률이 무지 높다.
특히 SGD가 취약 >> RMSProp, Adam같은 optimizer 사용
GD의 종류

* BGD(Batch Gradient Descent) : 전체 data를 사용해 loss 계산, 정확하나 느림
1. SGD (Stochastic Gradient Descent)
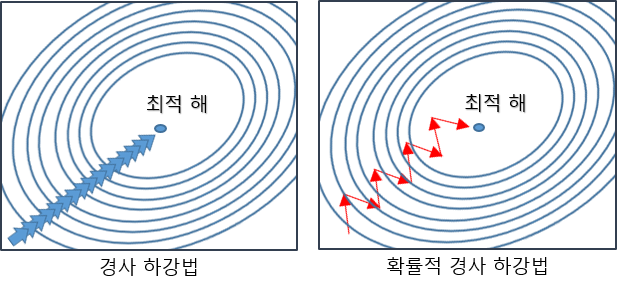
전체 data(batch)가 아닌 일부 datad의 모음을 사용하는 방법
한번에 하나 또는 일부의 훈련 샘플을 사용해 gradient계산하고 parameter 업데이트한다
BGD보다 부정확할 수 있으나 계산속도가 훨씬 빠르기때문에 같은 시간 많은 step을 나아갈 수 있음
-> 그러나 둘 다 local minimum에 빠짐
단점 : 1. 이동단계마다 하나/일부의 data만 사용해 gradient방향이 불안정하고 노이즈가 많을 수 있다
-> 업데이트 과정이 많을수록 노이즈가 증가
>> 해결방안 : SGD변형, momentum,AdaGrad 사용
2. Momentum

Global Minimum을 구하기 위해 Local Minimum에서 어떻게 빠져나올까?라는 생각에서 시작
-> 운동량을 이용하자! local minimum에 빠질때의 속도를 살려 빠져나가자
SGD가 접선의 기울기가지고 weight를 업데이트 했다면,
momentum은 현재의 기울기 + 이전의 기울기를 포함해 누적된 가속도로 weight update -> SGD에 관성개념 적용
현재의 w(weight)를 업데이트할때 이전의 w 업데이트양만큼 계속 가속도를 붙여 업데이트 속도가 빨라짐
이전 이동방향 기억하면서 이전 기울기 크기 고려해 이동
local minimum 빠질 수 있는 상황에서 momentum사용시 이전 기울기 크기를 고려해 추가로 이동하기에 빠져나갈 수 있다,
global minimum에 도달했을 경우, 추가적인 관성을 받아도 더 올라갈 수 없다
단점 : global optima에서도 이전 가속도가 더해져 추월하는 현상 발생
-> 이전 가속도를 조금 더 줄여 반영 .>> Nesterov momentum
3. Nesterov momentum (NAG)

Momentum : 눈을 감고 내려가는 것과 같다 (언덕을 내려가는 공으로 비유)
언덕을 다내려가고 다시 올라가기 전에 미리 알고 속도를 줄이자는 생각에서 출발
momentum은 현재 위치에서 기울기를 계산
NAG는 미래 위치를 추정해 거기에서 기울기를 구함
즉, 1. 현재 운동량을 가졌을 때 미래 위치 찾는다.
2. 미래 위치에서의 기울기 구한다.
3. 기울기 이용해 미래 위치 다시 구한다.
현재 g 이전 g 모두 구한 후 이전 g의 누적치 빼줌
-> 결과적, momentum보다 좀 더 추월하는 느낌, 그러나 성능 크게 향상 없어 momentum씀
4. AdaGrad

속도를 높이는 것보다 일직선으로 향하게 하는 방식
학습을 진행하며 이떤 변수는 많이 업데이트되고 어떤 변수는 적게 된다.
모든 가중치에 대해 동일한 학습률을 적용해야하는가?
많이 업데이트되는 변수는 적게, 적게 업데이트되는 변수는 많이 업데이트 할 수 없는가?
-> AdaGrad 등장
Adaptive Gradient의 약자 - 적응적 기울기
Feature마다 중요도, 크기들이 제각각이기에 모든 Feature마다 동일한 학습률적용하는 것은 비효율적
Feature별로 학습률을 Adaptive하게, 다르게 조절하는 것이 특징
장점: Feature마다 다른 학습률을 적용하므로써 학습을 효율적으로 도움
큰 기울기를 가져 학습이 많이 된 변수는 학습률을 감소시킴
학습이 덜 된 변수는 잘 학습되도록 학습률 높게 설정해 조절할 수 있다.
단점: g값이 점차 커져 학습이 오래 진행되면 학습률이 0에 가까워지기에 더이상 학습이 진행되지 않는다.
-> 즉, 학습이 잘 이뤄져 더이상 변수값들이 업데이트 되지 않는 것인지, g값이 지나치게 커져 학습이 되지 않는 것인 지 알기 어렵다.
>>해결방안 : RMSProp 제안
5. RMS Prop

Root Mean Square Propagation
AdaGrad가 학습이 진행될 때 학습률이 꾸준히 감소하다 나중에 0으로 수렴해 학습이 더이상 진행되지 않는다는 한계를 보완하기 위해 등장
AdaGrad와 마찬가지로 변수(Feature)별로 학습률을 조정하되 기울기 업데이트 방식에 차이를 둠
이전 time step에서의 기울기를 단순히 같은 비율로 누적하지 않고 지수이동평균(Exponential Moving Average; EMA) 활용해 기울기를 업데이트 함
즉, 가장 최근 time step에서의 기울기는 많이 반영하고 먼 과거의 time step에서의 기울기는 조금만 반영
경사의 크기에 따라 각각 파라미터 업데이트
이동평균이용해 크기 조절하기에 이전 기울기 크기와 현재 기울기 크기 비교해 크게 변하는 경우, 더 작은 학습률 적용해 안정적인 학습할 수 있다.
장점: 1. feature마다 적절한 학습률 적용해 효율적인 학습진행 가능
2. AdaGrad보다 학습 오래 가능
-> AdaGrad에서 g_{t} 계산할 때 g_{t-1}과 새로운 gradient값을 보정하지 않고 그대로 더했기 때문에 학습이 진행될수록 무한정 커짐. RMSProp은 감마를 활용해 g_{t}가 무한정 커지는 것을 방지해 오래 학습 가능
주요 특징 : 학습률 감소 -> 기울기 크게 변할 경우 더 작은 학습률 사용해 모델이 더 빠르게 수렴하도록 도움
이동평균 사용 -> 이전, 현재 기울기 크기 비교 -> 각 파라미터별 학습률 조절해 업데이트
파라미터별 업데이트 -> 각 파라미터가 서로 다른 학습 속도로 업데이트되어 모델의 학습을 더욱 개
6. Adam
Momentum + RMSProp
학습의 방향과 크기(학습률)를 모두 개선한 기법
딥러닝에서 가장 많이 사용되오던 최적화 기법
진행하던 속도에 관성도 주고, 최근 경로의 고겸ㄴ 변화량에 따른 적응적 학습률을 갖는 알고리즘
모멘텀처럼 진행하던 속도에 관성을 주고 RMSProp과 같이 학습률을 적응적으로 조절하는 알고리즘
참고 및 출처 : https://angeloyeo.github.io/2020/08/16/gradient_descent.html , https://hwk0702.github.io/ml/dl/machine%20learning/2020/05/28/GD/, https://yooloo.tistory.com/60 ,
https://nittaku.tistory.com/271,
https://wikidocs.net/194975 , https://docs.wandb.ai/ref/python/init , https://docs.wandb.ai/ref/python/log#docusaurus_skipToContent_fallback